OpenWRT 开启 SoftwareHardware Flow Offloading 后 iOS 通知推送延迟问题的溯源及一点解决办法
Archive 信息
| Archive 自 | Archive 创建于 | 分类 | 原始作者 | 原始地址 | 原始资源创建时间 | 原始资源更新时间 |
|---|---|---|---|---|---|---|
| CSDN | 2022-10-29 18:06 | 文章 | Chocola- | 链接 | 2022-03-11 11:32:40 | 2022-03-11 11:32:40 |
OpenWrt开启Software/Hardware Flow Offloading后iOS通知推送延迟问题的溯源及一点解决办法
实际上这个问题是我在将路由器刷成OpenWrt后偶然发现的。本来自使用的路由器是AX3 Pro,但是使用一段时间后发现这个路由器对IPv6的分配策略上有着不小的问题:本地运营商下发了/60的前缀后,此路由器并不会自动将此段地址切割以供二级路由使用,导致二级路由只能分配到/64的IPv6地址,无法继续下发地址,虽然在二级路由上可以使用NAT技术使下挂设备使用IPv6网络,但是这样显然违背了IPv6设计的初衷;其次,AX3 Pro默认将IPv6防火墙完全打开,同时无法在管理页面将此防火墙关闭,导致无法从公网访问到路由器后面的IPv6设备,这也明显阻碍了从外界管理内网设备的需求。所以,只能无奈舍弃这款路由器而选择可以刷入OpenWrt的路由器(OpenWrt对于IPv6及相关设置的支持良好),选择了搭载MT7621+MT7615的路由器解锁SSH权限并刷入了OpenWrt系统。


图1 MT7621官方数据参数
刷入系统几天后,偶然在一次聊天中发现iOS的消息通知推送有了延迟,通知框最迟的时候显示的是将近十分钟前的消息。于是用另一台设备发送测试消息,发现只要设备空闲超过两分钟,iOS的通知消息便有了明显的延迟。起初怀疑是官方的OpenWrt版本使用的都是开源驱动,对第三方设备的支持并不那么良好,于是自己拉取源码,修改编译选项将开源驱动换为MTK官方的闭源驱动编译出固件,再次刷入后发现问题仍然存在,但是后来换成完全基于MTK官方驱动且可以完全调用MT7621的硬件加速功能的Padavan系统后就不再存在消息延迟的问题。这个问题很令人感到困惑,本以为是驱动造成的问题,但是同样使用了闭源驱动,两个系统却有不一样的表现,只能是OpenWrt可能在某些关于网络的实现上有问题,但具体是哪里的问题,实在是不太好发现。于是在各个有关网络的论坛内搜索有没有类似的情况出现,终于在这个帖子内找到了遇到过类似问题的人: iPhone 推送通知延迟,这种情况出现在只连接 WIFI 的情况下。并且下面有网友给出了一种可能的解决办法。


图2 相似问题的帖子


图3 网友给出可能的解决方案

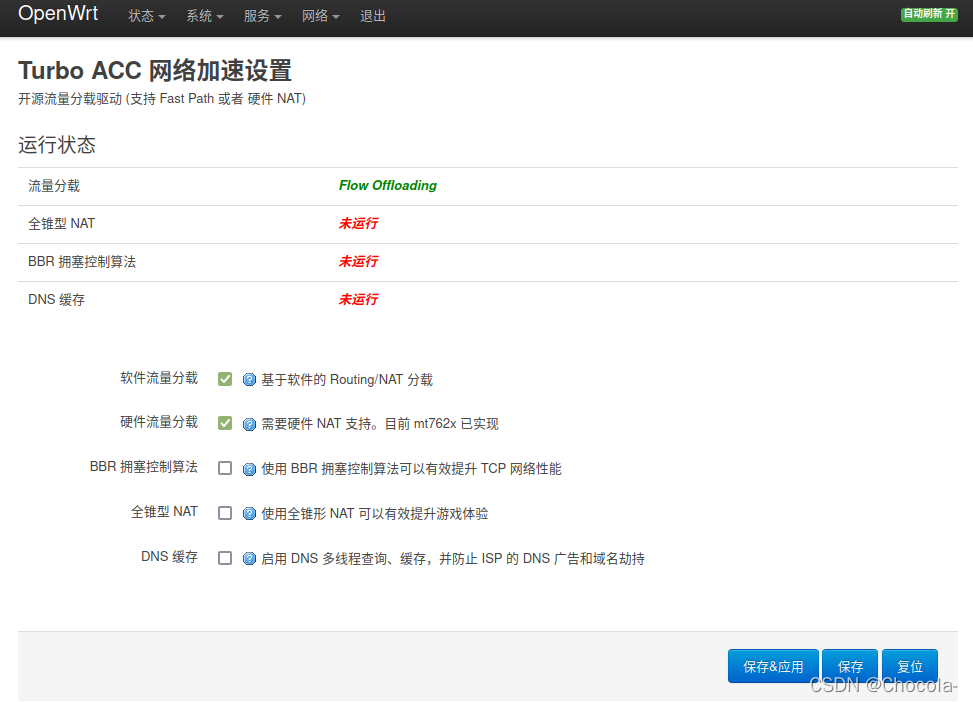
图4 自编译固件Turbo ACC管理页面
这里涉及到一些Apple设备的通知消息推送的机制,Apple设备的推送服务和主程序是独立的,每次Apple设备启动系统后,推送服务便创建一条与以下网段:
- 17.249.0.0/16
- 17.252.0.0/16
- 17.57.144.0/22
- 17.188.128.0/18
- 17.188.20.0/23
之中任一推送服务器的TCP长连接(事实上Apple Inc.拥有17.0.0.0/8一整条A类网段…),并每隔十分钟发送一次心跳包以Keep Alive。


图5 APNS使用的协议与端口
以上帖子是最接近解决问题的方法了,其他帖子甚至只有“同道中人”在反馈问题甚至没有任何可靠的解决方法。按照上面给出的方法在OpenWrt管理页面中关闭软/硬件加速,经过一段时间测试,确实消除了推送延迟的问题,但关闭此选项却带来了更大的问题:网速的极大下降。上面提到的MT7621参数表可以看出这颗CPU虽然有着双核四线程,主频仅有0.88GHz,但内置的硬件加速功能却可以带动上下同时1Gbps的网络流量。原厂固件一般搭配专用的闭源驱动来驱动这一功能:

图6 OpenWrt官方技术细节图片
首先系统通过将交换机下不同接口的数据打上不同的tag以区分内外网络流量,在搭配MTK官方闭源驱动时,驱动也会将内网数据包打上另一tag以区别是否在内外网络路由时进行硬件加速。因为驱动闭源OpenWrt自己重写了这部分代码,但通过查看这部分代码可知重写的部分仅实现了 LAN <–> WAN 有线部分的硬件加速,即仅对这部分数据包打上tag,而 WLAN<–>WAN 部分未进行任何处理,无法进行硬件加速,但可以借助Netfilter的OFFLOAD功能进行软件加速,虽然仍依靠CPU但对NAT网速的提升也不小。完全关闭加速后,数据的转发路由完全依靠这颗CPU进行处理,可想而知仅靠这颗CPU会对网速造成多大的影响。
既然关闭网络加速后有如此大影响,那这个网络加速功能为什么会导致推送延迟的问题呢?我在搜索引擎上换了各种关键词进行查找,可无奈的事能找到的全部中文帖子均未能给出原理性的解释,甚至有一些回答的解决方法看起来也不那么靠谱。。。可能是这个问题过于小众,也有可能是根本不会注意这几分钟的消息延迟,,,但既然涉及到数据包的转换,就应该可以从内核的Netfilter模块中找到一些问题,好在路由器这种嵌入式设备一般内核都会选用Linux,所以排查起来应该会方便一些。
通过SSH进入路由器Shell,通过iptables命令可以控制修改查看Netfilter模块,使用iptables -nvL -t filter查看表中所有规则,路由转发使用到FORWARD链,通过查看该链下的规则可以发现一些有意思的问题:


图7 路由器FORWARD链规则
链中规则是有先后执行顺序的,第一条规则仅起统计作用可以忽略不计,重点在于第二条规则:对于此条规则,不论数据包源自哪里目的哪里,只要经过内核转发建立连接或者与已建立连接相关联数据包,目标一律是FLOWOFFLOAD。这个FLOWOFFLOAD是什么?通过查阅Netfilter官方资料可由下图大致解释:

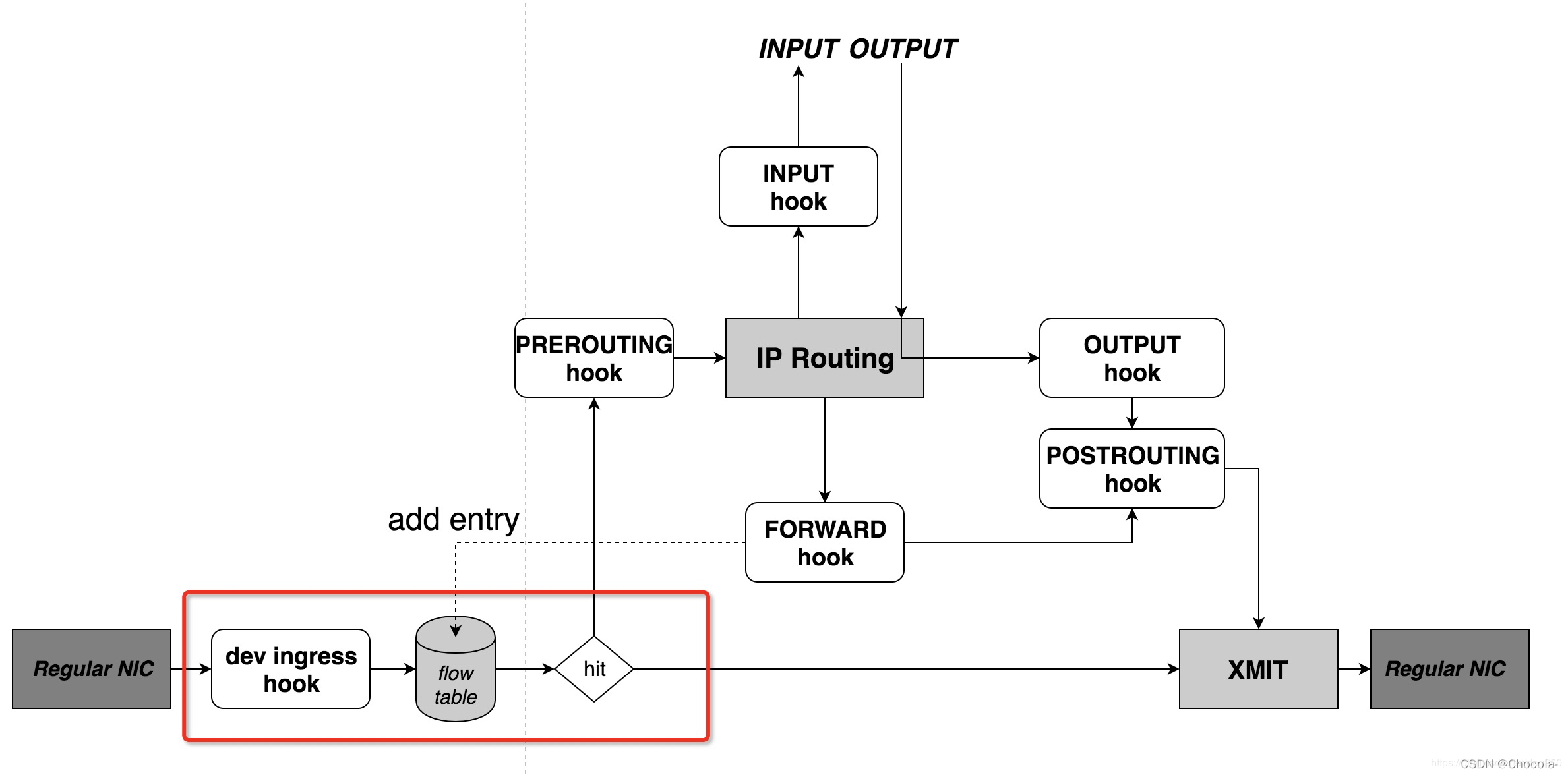
图8 Netfilter官方对于FLOWOFFLOAD的解释
不包括红框部分即是Linux内核对于数据包的处理路径,此时任何流经此设备的数据均交由内核处理,这便是关闭所有加速完全由CPU处理数据包的情况。在使用FLOWOFFLOAD功能后,可以看到多出了一个ingress hook。Netfilter官方对其解释如下:
The ingress hook was added in Linux kernel 4.2. Unlike the other netfilter hooks, the ingress hook is attached to a particular network interface.
You can use nftables with the ingress hook to enforce very early filtering policies that take effect even before prerouting. Do note that at this very early stage, fragmented datagrams have not yet been reassembled. So, for example, matching ip saddr and daddr works for all ip packets, but matching L4 headers like udp dport works only for unfragmented packets, or the first fragment.
The ingress hook provides an alternative to tc ingress filtering. You still need tc for traffic shaping/queue management.
简单来说,在多出这样一部分功能后,数据包的路径略有一些变化:
- 首先由网卡接收数据包进入ingress
- ingress匹配flow table(硬件/软件),如果命中则获取表中的路由项
- 解析路由项里的出口网卡dev_out,MAC地址等内容
- 递减TTL并直接交由dev_out发出,无需经过内核处理
- 未匹配成功则按传统路径交由内核处理。在FORWARD点出将信息注入flowtable
进入flowtable有一个条件,即完整地经过Netfiler路径,也就是一条流的双向包必须被FORWARD链都“看到”,才可将其从Netfilter中“卸下”。如何查看到被OFFLOAD包的状态呢?FLOWOFFLOAD功能依赖于nf_conntrack模块,可从/proc/net/nf_conntrack中查看到这些数据。向Apple设备发送消息唤醒推送服务后,在Shell中执行cat /proc/net/nf_conntrack | grep -w 5223可见:


图9 命令执行结果
可以看到设备与苹果APNS服务器的连接已经被从Netfilter中摘出(OFFLOAD),但奇怪的是隔一分半后继续执行该命令的结果:


图10 再次执行命令结果
第五列数据即为该连接的超时时间,明显可以看出,被OFFLOAD后的连接超时时间过短,这对于需要建立长连接的服务会有很严重的影响。在74s过后再次执行该命令可发现,该连接已经在表中消失了,也就是说在推送服务在无数据传送不到3分钟的时间里,该条连接就被路由器移除了!在之后的将近7分钟内(APNS心跳包间隔约为10分钟),向该设备发送的任何消息,因为与消息推送服务器连接被过早移除的原因,该设备都不会接收到来自服务器送达的任何数据,直至下次发送心跳包。
看起来在OpenWrt下推送消息延迟的原因找到了,但为什么被OFFLOAD包的超时时间是如此短?通过sysctl查询内核模块nf_conntrack相应的属性来看,flowtable的超时时间似乎与其不一致。执行sysctl -a | grep conntrack | grep timeout命令后:

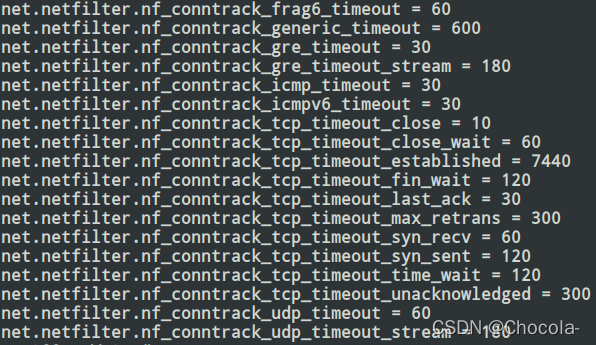
图11 命令执行结果
可以看到已建立的连接,established状态的连接超时时间为7440s,明显要大于几分钟的时间,这是什么原因呢?在OpenWrt官方论坛中,通过搜索conntrack与timeout关键字,找到了一篇名为《Software flow offloading and conntrack timeouts》的提问帖:Software flow offloading and conntrack timeouts,他也遇到了类似的超时问题,并发出了提问:
Then, after 2 minutes, the conntrack entry disappears. I would expect it to disappear after ~2 hours of inactivity, not 2 minutes.
Can anyone else confirm this behavior? Is it a bug?
Why doesn’t the count-down use the nf_conntrack_tcp_timeout_established value when it exits the [OFFLOAD] status? Where can I change the timeout that is used after the connection exits the [OFFLOAD] status?
下面有人回答了这个问题:
Q:Can anyone else confirm this behavior? A:Yes, flow tables evict inactive flows after 30 seconds, conntrack will then pickup the connection if there are any traffic in 120 seconds. Q:Is it a bug? A:This is quite unfortunate, but seems it is indeed deliberate, and not configurable: [02/38] netfilter: flowtables: use fixed renew timeout on teardown
回答说这个修改看起来是故意为之的,patch的内容如下:

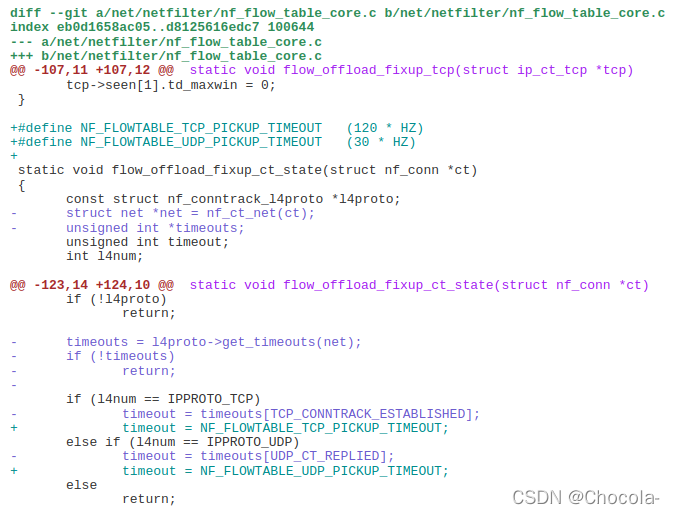
图12 Patch内容
查看编译时下载的Linux源码(Linux版本为5.4.175),修改此部分后的函数内容如下:
#define NF_FLOWTABLE_TCP_PICKUP_TIMEOUT(120 * HZ)
#define NF_FLOWTABLE_UDP_PICKUP_TIMEOUT(30 * HZ)
static inline __s32 nf_flow_timeout_delta(unsigned int timeout)
{
return (__s32)(timeout - (u32)jiffies);
}
static void flow_offload_fixup_ct_timeout(struct nf_conn *ct)
{
const struct nf_conntrack_l4proto *l4proto;
int l4num = nf_ct_protonum(ct);
unsigned int timeout;
l4proto = nf_ct_l4proto_find(l4num);
if (!l4proto)
return;
if (l4num == IPPROTO_TCP)
timeout = NF_FLOWTABLE_TCP_PICKUP_TIMEOUT;
else if (l4num == IPPROTO_UDP)
timeout = NF_FLOWTABLE_UDP_PICKUP_TIMEOUT;
else
return;
if (nf_flow_timeout_delta(ct->timeout) > (__s32)timeout)
ct->timeout = nfct_time_stamp + timeout;
}可以看出在修改前的超时函数中,TCP部分timeout的赋值是由TCP_CONNTRACK_ESTABLISHED提供,这个数值我们可由sysctl修改,OpenWrt默认值为7440。但是经过此次修改后timeout由定义的常量NF_FLOWTABLE_TCP_PICKUP_TIMEOUT提供,这个值被写死在了代码中为120,且flowtable不提供对外修改其属性值的可能性。除非在编译内核前修改相关值,否则只要运行系统启用FLOWOFFLOAD功能,TCP连接超时时间便恒定为120,且独立于conntrack模块的TCP超时时间,不受其影响。
因此,只要开启了FLOWOFFLOAD功能,长连接的超时时间便恒定为120s;但若是放弃这一功能,网速的巨大下降又是另一个大问题。如何解决这种冲突呢?那个帖子下面没有回答这个问题。一种办法是直接在编译前修改这一部分的定义,更改TCP超时时间,但存在风险,因为这一部分的内核代码由OpenWrt修改过,与官方主线内核代码存在一定的差异,没有完全理解这一部分代码前盲目修改其中内容,可能会因修改错误导致编译失败。另一种办法是移植最新的5.15 LTS版本内核过来,在这一版本中这一问题被修复了,但这种办法的困难可能更大。
有没有什么能折中一点的办法解决这个问题,我个人想了一个其他办法。观察图6可以看出对于FORWARD链来说,经 WAN<–>LAN/WLAN 转发的流量一律使用了FLOWOFFLOAD功能,能不能修改一下规则让5223端口的转发流量不使用FLOWOFFLOAD功能呢?还是可以的,链中规则是按照先后顺序匹配执行的,只要在执行OFFLOAD这条规则之上添加规则,这样根据从上至下的匹配规则,对5223端口的流量一直交由内核处理,应该就可以解决这个问题。根据iptables的规则,执行如下两条命令并将其加入启动脚本中随系统启动执行:
iptables -I FORWARD -p tcp --sport 5223 -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
iptables -I FORWARD -p tcp --dport 5223 -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT执行后FORWARD链变为下图: 

图13 命令执行后的FORWARD链
此时向Apple设备发送消息,唤醒消息推送服务后,执行命令cat /proc/net/nf_conntrack | grep -w 5223后的结果如图:
![]()
![]()
图14 修改FORWARD链后命令执行结果
可以看到,与Apple通知服务器的连接已经不交由FLOWOFFLOAD控制,此时的超时时间为conntrack模块默认TCP超时时间7440,远超心跳包发送周期10分钟。经过一段时间的使用发现Apple设备的消息推送服务不再有延迟了。
别看最后解决办法只有短短两条命令,但这个问题着实困扰到我几天时间,因为无论怎么调整关键词,中文回答里找不到半点对问题原因的分析。。。唯一有启发的回答还是在一个帖子犄角旮旯的角落里(百度是真的不靠谱)。另外为了弄清楚flowtable的原理,不得不粗略的把这部分的内核源码读了一遍。虽然到最后只能想了这么一个指标不治本的办法,但总归是把这个困扰了几天的问题解决了,现在回过头想想解决这个问题的过程还是挺有意思的o( ̄▽ ̄)o。因为本人能力有限且文笔相当的不好,对某些内容的理解表述可能会出现偏差,懂行的朋友如果看到了还望轻喷 = ̄ω ̄=。
 絢香猫
絢香猫